東海道新幹線に忘れ物をしてから手元に戻るまで
先日義理の実家に弔事の予定で帰る際に、東海道新幹線車内に礼服一式を忘れてしまい、その後手元に戻るまでの流れを備忘録がてら書き残します。
忘れたもの:ガーメントバッグ
手元に戻るまでの日数:3日
タイムライン
9/14
7:46 新横浜駅からのぞみ498号に乗る。キャリーケースを足元に置いて、ガーメントバッグを網棚に置く。
8:03 東京駅で下車。ここでガーメントバッグを網棚に忘れる。「この列車は車庫に入る回送列車です」とアナウンスがある。
8:22 とき307号に乗車し、発車
8:23 発車直後に忘れ物をしたことに気づく
8:30くらい JR東海お忘れ物問い合わせフォームに問い合わせる
11:00くらい 忘れ物のデータベースに合致するものはないと返答がある
17:00くらい JR東海お忘れ物問い合わせフォームに問い合わせる(2回目)
18:00くらい 忘れ物のデータベースに合致するものはないと返答がある
9/15
9:00くらい JR東海お忘れ物問い合わせフォームに問い合わせる(3回目)
11:00くらい それらしきものが東京駅に届いていると返答がある
9/16
10:20 JR東海から電話を着信。忘れ物についての詳細を口頭で確認。その日のうちに佐川急便で着払いで発送すると伝えられる。
9/17
9:00くらい 自宅で受け取り
JR東海のお忘れ物の問い合わせ
電話はまずつながらないと思ったほうがいい。なので基本Webで問い合わせることになる。
忘れ物が届いていない、データベースに登録されていない場合はこのようなメールが数時間後に届く。

忘れ物が登録されている、届いている場合はこのようなメールが届く。

どこに届いているかも記載されているので、これが届いた時点でその駅に赴くのが最速で手元に戻る方法となる。自分は山形にいたのでそれはできなかった。
また、当日中に電話はかかってくることはなく、翌日に電話がかかってきた。そこでまず忘れ物の詳細(バッグに入っていたものはなにか、どの列車の何号車に忘れたか、など)を聞かれ、確認が取れたのちに、着払いで自宅に送ってほしいと申し出た。その日のうちに佐川急便で発送いただき、翌日朝一で横浜の自宅にとどいた。着払いで支払った金額は2,580円だった。
佐川スマートクラブに登録しているが、お荷物お届けの事前通知はなぜか来なかった。
忘れた原因や気づきなど
- そもそも自分はヤバい忘れ物を滅多にしないので、いざ忘れ物をするとパニックになる。弔事に参加するのに喪服一式を忘れるとかいう最悪の事態になってヤバかった。
- 新横浜で座った自由席から品川で空いた一列後ろに席を移動した。普段なら降りるために立ち上がるときに網棚の荷物が視界に入るが、一列後ろにずれたので視界に入らなかった。
- 東京駅で乗り換えた先が別会社のため、乗り換えた列車を降りた駅で直ちに問い合わせられなかった。
- 乗ってきた列車が大井車両基地に行ったため、忘れ物の捜索がすぐにされなかった。結果としてデータベースへの登録が遅かった。
- 東京行きに乗ったからJR東海だけの問い合わせで済んだが、逆向きだったら西日本の可能性もあるし、遠くの駅に届いていて自宅に到着するまでに時間がかかった可能性がある。
- スーツの内側に名前の刺繍が入っていたので、忘れ物照合が比較的容易だった。
再発防止策など
- むやみに自由席を移動しない
- (もし気づくことができたら)降りた駅の窓口で直ちに問い合わせる
- お問い合わせフォームには1日朝夕くらいをめどに何度も問い合わせる
- 警察署に移管されるとさらに面倒だと思うので、見つかったら直ちに取りに行くor電話をすぐとれるようにする
- 東京駅お忘れ物承り所の受付時間は、8:30~20:00と意外と短い
以前、東急新横浜線に日傘を忘れた妻は、東急・相鉄・東京メトロ・都営地下鉄などかなり多くの鉄道会社に問い合わせることになった挙句、結局見つからなかった。相互乗り入れの列車に忘れると悲惨。
結婚前同棲時の金銭管理をどのように行うか
最近は結婚前に同棲をするケースが多く、自分もこのパターンです。結婚する前にお互いの生活の価値観が合うか、許容できるかを判断することができ、もしダメでも離婚するよりも比較的障壁なく解消することが可能です。
その価値観の一つとして金銭感覚があります。同棲時の生活費の捉え方が異なる場合、トラブルに発展してしまう可能性があります。結婚しているとクレジットカードで家族カードが発行できたりなど、決済面でけっこう融通が利きますが、結婚前の同棲ではそうはいきません。ですが、同棲では二人で完全に区別できない支出がいくつかあります。これらを効率的に透明性を持たせて管理する方法を、過去に当時の彼女に同棲前にプレゼンをしたことがあるので、その内容を共有します。
(情報が古い場合があります。最新の情報は自分で調べてください)

支出の種類

ここでは支出の種類を2つに分け、個人支出と共同支出と定義しました。2人で一緒に消費するお金(=明確に分けることができないお金)の管理方法が今回のメインテーマになります。
個人支出の取り扱い
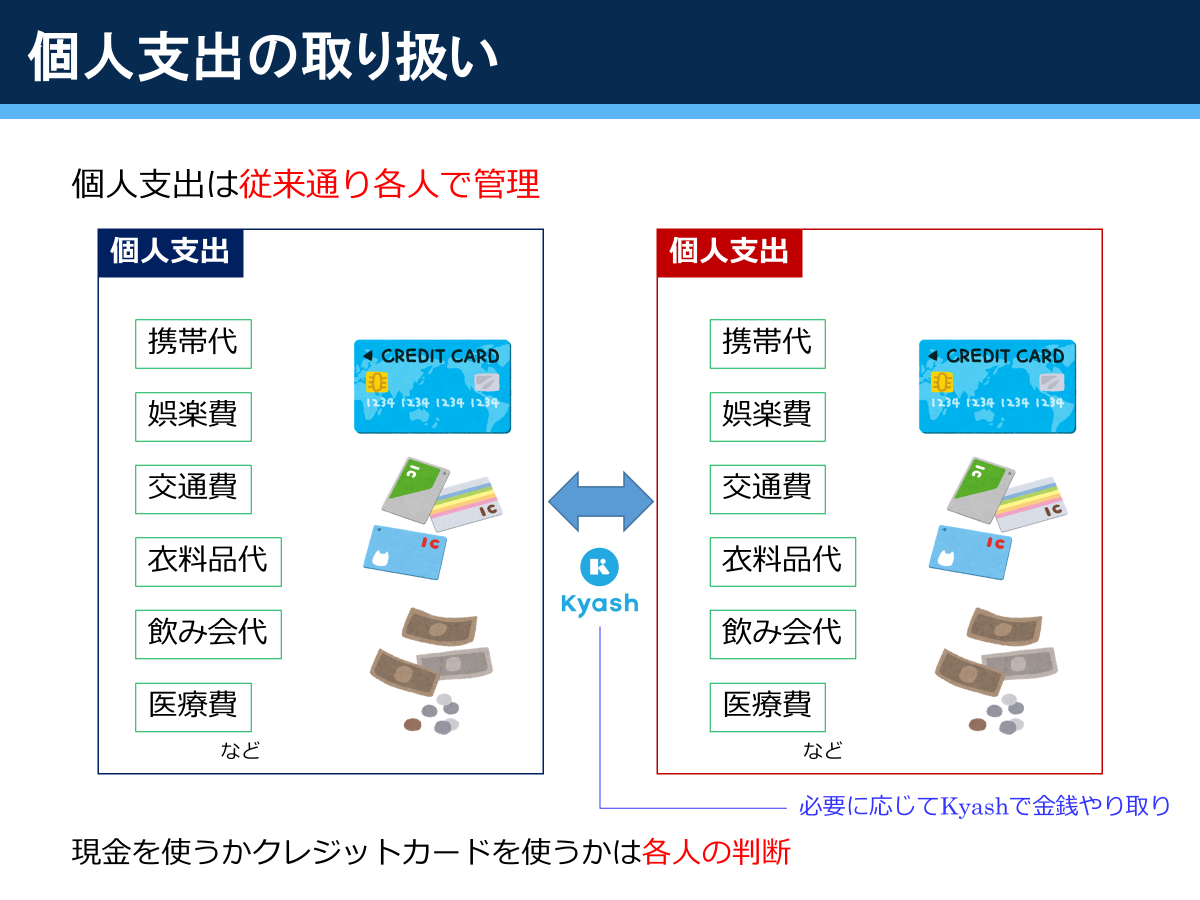
娯楽費をはじめとした「自分のための支出」は自分で管理し、毎月の共同支出のための生活費を捻出できれば、お互い相手の金の使い方には口出ししないようにしています。割り勘とかをする場合はKyashを使っています。食費についても、2人で家で食べたり外食したりする分は共同支出、通勤途中にひとりでその辺で買い食いしたりカフェに入ったりする分は個人支出と分けています。
ここでは医療費も個人支出となっていますが、お互いの健康は家族にとっての資本ですので、結婚を機に医療費は共同支出の枠に移動しました。また、結婚後はマイカーも二人の資産になるので、自動車関連費も共同支出の枠に移動しました。
共同支出の管理にあたって

お金はとにかくトラブルの元になるので、徹底した管理が求められます。具体的には、「支出を明確にする」ことが必要になります。その手段として「クラウド家計簿」と「キャッシュレス」が有効です。

この2つを連携させることで、「明確に」「自動的に」管理することができると考えています。「明確に」は当然として、「自動的に」できるのはずぼらな自分らにとって大きなメリットになりました。お金を使うとMoneyForwardから通知が入るので、2人のお金を内緒で勝手に使うことがほぼできないシステムになっています。
共同支出の管理方法

上図が共同支出の管理方法の概要です。基本的にクレジットカード決済が前提でポイントを貯め、やむを得ない場合にのみ銀行引き落としにします。水道ガス電気は変動費となっていますが、ほぼ固定費と考えてもいいと思います。結婚後もこの運用を続けています。
共同支出の管理の問題点
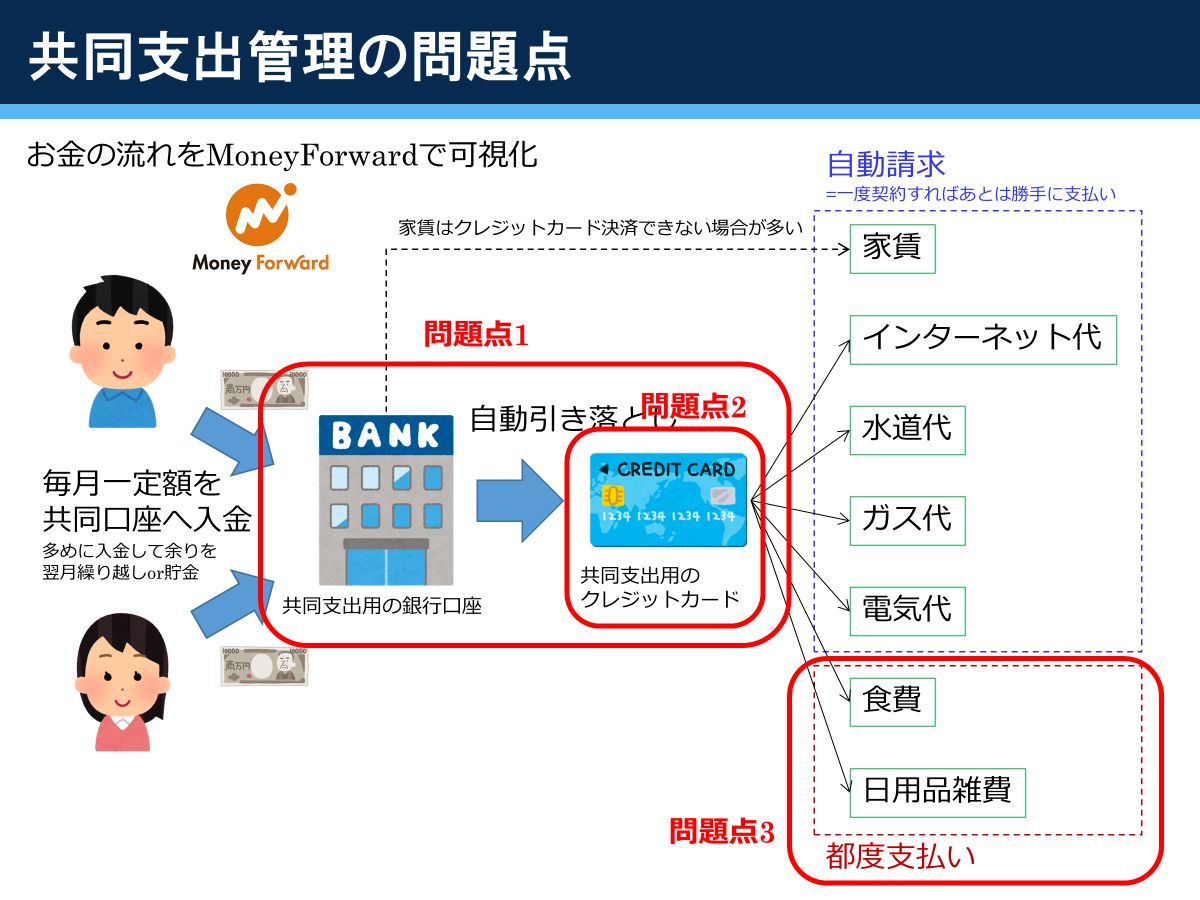
共同支出の管理をするときに、大きく3つの問題点が挙げられます。

自分は個人用に楽天銀行を持っていたので、新たに自分名義で住信SBIネット銀行口座を開設しました。彼女の個人口座も住信SBIだったため、振込手数料がかからないというメリットがありました。目的別に口座を作ることもできるので、結婚後も使っています。ですが、結婚後にローンを組んだり公的機関にお金を支払ったりするのにネット銀行よりもメガバンクや地銀のほうが良いケースがある(自分の地域の保育料引き落としはネット銀行非対応だった)ので、カーローン組むときに地銀の口座を追加で開設しました。
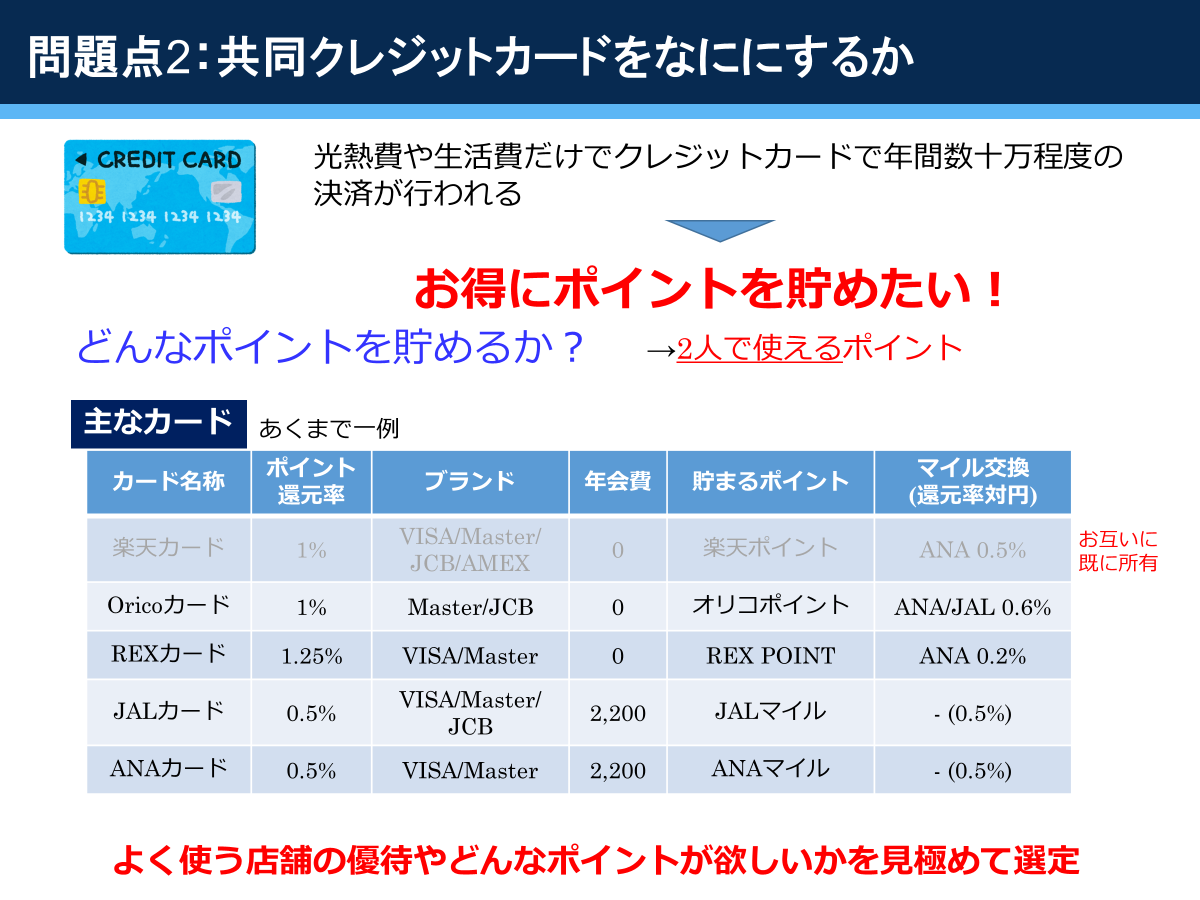
同棲開始時は結局オリコカードを作りました。オリコポイントはAmazonギフト券に全部変えて、Amazonで日用品を買っていました。しかし、オリコポイントの交換レートが年々悪化してきているのと、MoneyForwardで手動更新が必要なのが面倒だったので、結婚後にオリコカードをやめて三井住友VISAゴールドカードに変え、家族カード、ETCカードを発行しました。ゴールドカードの年会費は年間100万つかうと永年無料になります。生活費等を支払っていたら余裕で100万円を超えます。ポイント還元率は0.5%ですが、100万円使ったタイミングで10000ポイントもらえるので、平均1%は超えるでしょう。VポイントはiD連携してすぐ使えるのがいいですね。

といったような問題が普段の買い物で発生しえます。そもそも他人名義のカードで買い物をしてはいけません!個人で出して立て替えることが許容できるならそれでいいと思います。
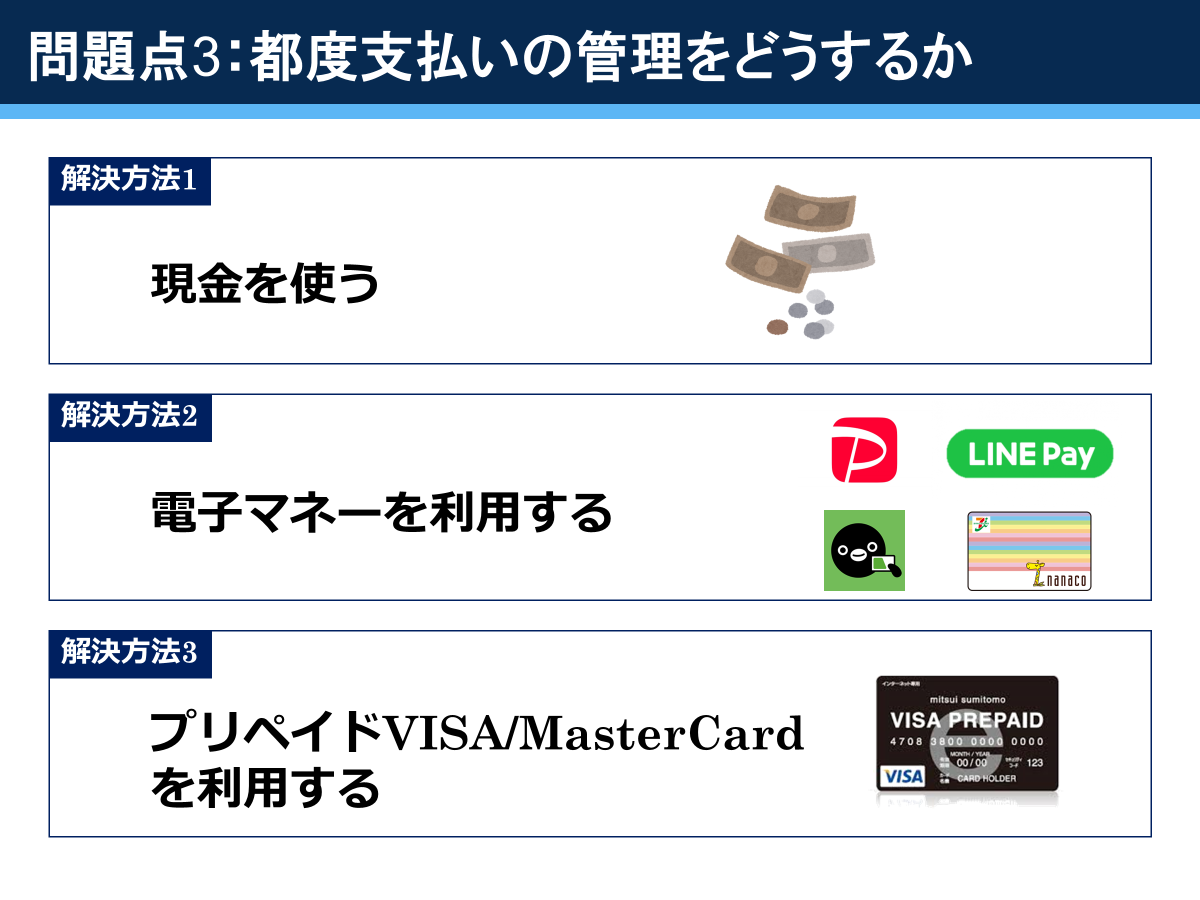
この問題に対して3つの解決策を提案しました。

現金主義の方は家計が直感的に記録できることに価値を感じているようで、自分の妻もそのような考えで個人支出は現金で管理しています。ですが、それは自分の中で完結しているからできるのであり、他人の財布の中身を把握するのはかなり困難です。なので、病院や個人商店など、現金決済しかできないところに限って現金を使うようにしています。あと都度手動記録だとお互い忘れますね。

同棲前に引越先の周辺のお店を回り、使える決済方法を確認しました。どこもだいたいなんでも使えたので、結果的にあまり気にする必要がありませんでした。

上図のように、チャージ方式の差を示していますが、電子マネーへのチャージは基本的に自分名義の銀行口座、クレジットカード、もしくは現金にしか対応していないので、家族カードが発行できない同棲時は難しく、結局採用しませんでした。

最終的にANA JCBプリペイドを二人分発行しました。ANA JCBプリペイドは他人名義のクレジットカード(JCBブランド限定)でチャージができるので、同棲時には非常に便利でした。また、ANA JCBプリペイドはクラウド家計簿の自動記録に珍しく対応しており、すべての問題を解決してくれました。ANAマイルも貯まるのでポイ活面でも利点があります(我が家は帰省時にANA便を使う)。しかし、チャージする際にいちいちブラウザでマイページにログインしてチャージ作業をする必要があり、これが非常に面倒だったので、結婚して家族カードが発行できるようになったのを機に使うのをやめました。
透明性の確保

透明性を確保するために、新たにお互いがアクセス可能なGoogleアカウントを作って、共同支出に使うサービスはこのアカウントのメールアドレスを登録しています。金融機関以外にも、インターネット、電気、ガス、水道、MoneyForwardなど、2人で使うサービスにはこの共用アカウントのメールアドレスを登録しています。
まとめ
- 金銭トラブルを防止するために個人支出と共同支出をしっかり分ける
- 共同支出を互いに明確にすることで金銭トラブルを防ぐ
- クラウド家計簿とキャッシュレスを組み合わせて、家計簿が自動的に記録されるシステムを構築する
- 共同銀行口座と共同クレジットカードを作る
- 共同口座は収入が多いほうの名義で作る
- クレジットカードはよく使う店舗の優待や欲しいポイントを見極めて選定
- 都度支払いを柔軟にやるには共用クレジットカードだけでは限界がある
- 都度支払いを現金でやるとレシートをとって都度記録が必要
- 都度支払いに使う電子マネーの選定には近所のお店で対応をしているか確認
- プリペイドVISA/MasterCardはポイントが貯まるが、MoneyForward連携非対応
- 各サービスを共有するために共用メールアドレスを作成して登録
ここまで考えてやってきたので、今は我が家の財務大臣は自分になっています。MoneyForwardにも課金し、予算機能を使いつつまめにチェックしながら生活費をコントロールしています。
決済サービスは変化が激しいので、自分のスタンスに則ってそのときにあったサービスを使うのがいいかと思います。ほかにも良い決済サービスや金銭管理方法があれば教えてください。
横浜市港北区保育園の入園難易度考察(令和6年)
横浜市は保育園への入園倍率が高く、保育園に落ちて親の社会復帰ができないことが多いことで有名です。少なくとも両親共働きで祖父母のサポートが受けられないという環境でないと、0-2歳で保育園に入ることは難しいとされています。申請時に第20希望まで保育園を書く人もいるようです。保育園に入れないことを理由に、横浜を出て藤沢市や大和市のほうへ引っ越す人も少なくないと聞きます。
しかし、横浜市といってもその入園難易度には市内で地域差があるはずで、その地域差を分析すれば横浜市に住みながら保育園の問題を解決できるかもしれません。そこで特に保育園激戦区と言われる横浜市港北区を例に、字単位でその倍率と地価の関係を可視化してみました。結婚や引越等で新たに港北区で家を探している人の参考になればと思います。
入園させやすいコツ等については言及せず、今回は保育園の入園倍率の地域差にのみ言及します。
ちなみに我が家の0歳児は無事に区内の保育園に受かりました。ですが、近所の同級生の中には落ちてしまった人も一定数いました。
使用したデータ
令和6年度 保育所等 新規利用見込数
令和6年4月二次入所の受入可能数(見込み)
https://www.city.yokohama.lg.jp/kohoku/kurashi/kosodate_kyoiku/hoiku/hoikujo/hoiku.files/0207.pdf
神奈川県地価公示価格一覧(令和5年)
https://www.pref.kanagawa.jp/documents/97040/05kouji_shiryou02.pdf
計算方法
認可保育園のデータのみで計算しています。
保育所のキャパシティ
=入所児童数+新規利用見込数
保育所倍率
=(保育所のキャパシティ+延べ待ち人数-二次入所受入可能数)/保育所のキャパシティ
※4月からの0歳児クラスは入所児童数は0として計算します。
地区ごとの保育所のキャパシティ
0-5歳までの受け入れ可能人数の総数を保育所の所在地区ごとに表したのがこちらの地図です。色がない地区には認可保育所がありません。(新吉田町、大曽根台、高田町、北新横浜、鳥山町、篠原東)

真ん中の1176人のキャパシティをもつのは大倉山です。実際に保育園の数がたくさんあります。続いて北部の日吉や綱島のキャパシティが多くなっています。これらの地区は東急東横線沿線になっていて、東急線で都内へ通勤する親にターゲットを定めて保育所を設置している傾向がありそうです。一方で西部の高田西、新羽町、小机町は地区の面積に割にキャパシティが少なくなっています。グリーンライン、ブルーライン、横浜線が通る地区ですが、どれも都内に直通しない路線です。都内に直通するかしないかでここまで差が出るかという感じです。
地区ごとの保育所倍率
次に0-5歳までのトータルの倍率を地区ごとに表しました。色がない地区には認可保育所がありません。(新吉田町、大曽根台、高田町、北新横浜、鳥山町、篠原東)

1.5倍を超えているのは、日吉、箕輪町、小机町の3地区です。日吉・箕輪町は保育所の数は多いですが、最近大規模マンションがたくさん建ってファミリー層が多く流入してきている影響で倍率が高くなっているようです。特にベネッセ日吉保育園が有名で、延べ入所待ち人数が183人となっています。一方で小机町は、最近宅地開発が進んでいますが、先述の通り保育所のキャパシティがそれに追いついていないようです。
以下年齢ごとに倍率を見ていきます。

0歳であれば多くの地域において1倍前後でまだ入りやすくなっています。1歳だと一気に倍率が上がるので、確実に保育園に入れたい場合は0歳から入れる、というのがセオリーになっています。ですが、日吉、新羽町、小机町では0歳の時点ですでに1.5倍を超えてしまっています。日吉周辺は子供の数が多いのだと思いますが、新羽町や小机町はまず保育園の数が少なすぎます。また、小机町や新羽町は面積で見ても広いので、保育園が遠くなってしまうことが多く、送迎が大変になることが予想されます。なので、いったん新横浜駅前まで出てきて、そこで子供の送り迎えをして通勤、帰宅するという方法も一つの手です。新横浜駅前の保育園は比較的0歳の受け入れ可能人数が多くなっていて、倍率も1を切っています。

1歳で保育園に入るのはかなり困難であることがデータからわかります。日吉、箕輪町、小机町では約3人に1人しか入れない計算になります。これでは両親共働き要件では厳しく、プラスαで加点要素が必要になってきそうです。そんな中でも大倉山を中心とした港北区中部は、激戦と言われる1歳児でも定員割れるか割れないかの倍率です。保育園に入れるか心配な人は大倉山周辺に住む、もしくは通勤経路に組み込むのがよさそうです。

3歳児ともなれば、保育士一人当たりが見ることができる人数が増え、キャパシティが増えるので倍率がどこも1倍前後で需給バランスがよくとれるようになりました。
注目すべきところは、港北区中部の大倉山、大豆戸町、師岡町、大曽根、樽町は比較的年齢ごとの倍率の変動が少なく、かつ1倍前後となっており、保育所の需給バランスがすべての年齢児で優れている地域と言えます。特に住みにくい地域というわけでもないので、保育園に入れるか不安な人は住む候補として上位にあげていいでしょう。他地域に比べて、マンションよりも戸建てが多そうな地域なので、単位面積あたりの世帯が少なく、結果として子供の数もちょうどよくなっているのかもしれません。また、大倉山には「どろっぷ」という港北区の地域子育て支援拠点があります。区内の未就学児の子育てをしている親子が集まる拠点のような施設で、とても良いところです。特に祖父母の支援が受けられない、まわりに子育て仲間がいなくて相談できる相手がいない、などといった状況の方にはとてもオススメできるところです。そういった施設があるのも大倉山の強みになっています。
裏を返せば、タワマンの近くに住むのは保育園の観点からは良くないと言えます。
地価との相関
まず令和5年の宅地の地価を地図に表します。色がないところは宅地地価のデータがない地区です。

区内東部を南北方向に赤くなっていて、わかりやすく東急東横線沿線の地価が高くなっています。綱島と大倉山の間の鶴見川南側(樽町、師岡町)は比較的安くなっていますが、この地区は駅までけっこう遠いです。また、この地区に限らず鶴見川流域はどこも等しく洪水リスクがあるので、そのリスクによる地価への影響は小さいかもしれません。
地価と保育所の倍率で地区ごとにプロットしたグラフを示します。

先で散々出てきた日吉、箕輪町、小机町を除くと正相関が取れそうです。地価が高い→人気の地区で新たにファミリー層が増える→保育園の倍率が上がる、といったストーリーが描けそうですが、裏付けのためには地区ごとの世帯と年齢の情報が必要です。
逆に、急速な宅地、マンション開発が進む地域はこの相関に乗らない特異点になってしまっていました。他のタワマン開発が進む市区でも同様の傾向が出るか見てみるのも面白そうです。
まとめ
港北区のようなTHEベッドタウンでは全体的に保育所のキャパシティが不足しています。ただし、そうは言っても地区ごとに差はありました。戸建てが多い地域は保育所の倍率が低く、一方で急速な宅地、マンション開発が進んでいる地域は保育所の倍率が高くなっている傾向になりました。保育所の心配をしている方の引越先の参考になれば嬉しいです。
宅地、マンション開発をするときに行政と保育所の不足についての協議はしたりしないのでしょうか。そこがうまく連携できるとよりよい街作りができそうな気がします。(百合子はその連携を頑張って都内の待機児童問題を解決したのかな)
参考
参考というか影響を受けた書籍を紹介します。ジャンル問わず様々なデータを分析していて面白いです。

2024.06.04 追記
最近open-hinataというウェブサイトで地図上で統計を見ることができることを知りました。
このサイトで保育園倍率の高い箕輪町と低い大倉山の人口ピラミッドを見てみました。最も人口の多い丁目で見ています。


箕輪町2丁目の人口ピラミッドがものすごい形をしていました。0-4歳、35-39歳の人口が地区内でトップになっており、若いファミリーがたくさん住んでいる地域であることがわかります。(箕輪町2丁目にはプラウドシティ日吉があります。)一方で大倉山5丁目はいわゆるつりがね形をしていて年少人口が少ないです。可視化してきた倍率の根拠がこれで見ることができて非常に興味深いですね。
結婚式でアニソンを流したい!
先日無事に結婚式と披露宴を行うことができた。我々オタク夫婦が結婚式で流した音楽(主にアニソン)でけっこう演出がうまくいったのと、JASRAC管理の音楽ならなんでも流せると思ったら全然違ったのが興味深かったので、今後挙式予定のオタクカップルのために結婚式と音楽について残す。
※式場によって取り扱いが違うと思うのであくまで参考です
結婚式で流せる音楽
結婚式で流せる音楽は「記録映像に残すかどうか」「演出として使うか」どうかで決まる。映像に残すということは音楽の複製商用利用にあたるので、著作権申請が必要らしい。特に記録映像として残すつもりがなければ、基本著作権管理されているものであればなんでも流せる。また、映像として残す場合でもBGM利用の場合(歓談中・食事中など)は特別な著作権申請は不要だった。音楽を演出として使う(入場、ケーキ入刀、ブーケトスなど)場合は、特別な著作権申請が必要だった。
そして必ずCD原盤を用意して音楽を流さなければならないルールになっている。最近はサブスク等で音楽を聞くことが多くCDを買わないので、今回は頑張ってメルカリとブックオフでCDを収集した。アイマスのライブ会場限定CDみたいなプレミアついてるCDに収録されている曲を使おうとなると相応の覚悟がいる。配信しかない音楽の場合はデータでもOKだった。
自分が挙式した式場は映像に力を入れているところだったので、著作権申請はマストだったが、そうではない式場であればそこまで深く考える必要はないと思う。
式場見学の際はJASRAC登録曲ならなんでも流せると説明されるが、このへんの話を知っておくと見学の際に質問できると思う。
ブライダルシーンの著作権申請
著作権申請を自分で行うこともできるが、非常に手間になる。そのため、ブライダルシーン向けに代理で著作権申請をまとめて行ってくれる音楽特定利用促進機構(ISUM)という組織がある。
この組織が著作権申請をして許可をとってくれ登録された楽曲は、誰でも使用料を払えば結婚式に使用できる。有名なJ-POPはだいたい登録されているが、アニソンやゲームソングなどは登録されている曲が少ない。だが登録されていない楽曲は著作権申請リクエストができる。もちろん、必ずしもリクエストが通るとは限らない。オタクが好きな曲を流すにはこの著作権審査に通過する必要があるのだ。
そして登録されていたアニソンのジャンルの傾向がおもしろかった。
・女性向けが多い
だいたい結婚式準備に熱が入るのは新婦なので、おそらく新婦がリクエストしていることが多いと考えられる。アイドルマスターミリオンライブ・シンデレラガールズよりも圧倒的にsideM曲が多い。ラブライブも比較的女性人気が高いのか、キャラソンまで異様に充実していた。
・声優ソロ曲が多い
水樹奈々やLiSA、田村ゆかりなどひとりで歌う曲は著作権申請を通すところが少ないのか登録楽曲が多い。逆にアイマスや特定のアニメの声優グループ曲など、複数のアーティストが歌う楽曲はリクエストが通りづらいらしい。
・ディズニーや洋楽は少ない
おそらく申請がめちゃくちゃ大変なんだと思う。
ISUMが著作権申請できるのはJASRACが著作権管理している楽曲であることが大前提だが、一部JASRACが著作権管理していない楽曲がある。その例がKey楽曲だ。
Key作品の音楽はVisual artsがKey Sounds Labelとして独自に著作権管理している。Keyの音楽はBGM利用であれば特別な申請なしで利用できるとのこと。実際に今回はガルデモのThousand EnemiesをBGMとして使用した。
製品内の素材の使用に関するQ&A|Key Official HomePage
リクエストして通った楽曲
全部で20曲以上リクエストしたが、通ったのは以下のみ。正直通過率は低い。申請から登録まで1か月~2か月かかるので早めに動くのがよい。
- オリジナルスター☆彡 / わか・ふうり・すなお・れみ・もえ・えり・ゆな・りすこ from STAR☆ANIS
- ハッピーアイスクリーム! / チーム フォルトゥーナ(倉田亜美(CV.東山奈央)、新垣葵(CV.五十嵐裕美)、西條雛子(CV.大久保瑠美)、一之瀬弥生(CV.黒澤ゆりか)、高宮紗希(CV.日笠陽子))
- Enter Enter MISSIONです! / 浜口史郎
- 劇場版・乙女のたしなみ戦車道マーチ! / 浜口史郎
- 劇場版・大洗女子学園チーム前進します! / 浜口史郎
ガルパンのサントラも通ったり通らなかったり、アイカツ曲もオリジナルスターは通るのにカレンダーガールは通らなかったりと、基準がよくわからなかった。カレンダーガールは個人的にめちゃくちゃ使いたかったので残念。
また、自分が浦和レッズサポなので、First Impression(選手入場曲)を使いたかったが、これもリクエストが通らなかった。
自分の実際のセットリスト
参考までに実際のセットリストを紹介します。
新郎の好きなコンテンツ:アイマス、Angel Beats(ガルデモ)、けいおん、アイカツ(曲だけ)、とあるシリーズなど
新婦の好きなコンテンツ:ラブライブ、ウマ娘、プリキュア、ゴールデンカムイ、ヒプマイなど
ふたりの共通で好きなコンテンツ:ガルパン
ふたりで共通で好きなジャンルがガルパンしかなくてかなり揉めたが、最終的にすごく良いセットリストになった。
- フラワーシャワー:劇場版・戦車行進曲!パンツァーフォー!/浜口史郎
- ブーケトス:劇場版・乙女のたしなみ戦車道マーチ!/浜口史郎
- 入場:Make debut!/スピカ
- 乾杯:パーティーを止めないで/伊弉冉一二三(CV. 木島隆一)
- ケーキ入刀:オリジナルスター☆彡/STAR☆ANIS
- 新婦中座:Love wing bell/星空凛
- 新郎中座:M@STERPIECE(オリジナルカラオケ)/765PRO ALLSTARS
- お色直し入場:ユメヲカケル!/スピカ
- 各卓キャンドルサービス:SUMMIT OF DIVISIONS/ヒプノシスマイク
- 新婦手紙朗読:あなた/いきものがかり
- 親記念品贈呈:虹の音/藍井エイル
- 退場:Enter Enter MISSIONです!/浜口史郎
- プロフィールムービー新郎:J'S THEME(Jのテーマ)25th ver./春畑道哉
- プロフィールムービー新婦:僕たちはひとつの光/μ's
- プロフィールムービー二人:Rally Go Round/LiSA
- エンドロール:ray/BUMP OF CHICKEN feat. HATSUNE MIKU
これとは別に歓談BGMを12曲ほど用意したが、おそらく1周はしていたと思う。会場の演出スタッフ、音響スタッフと設備がすばらしく、すごく良い式になった。
よかったところともう少しなんとかできたところ
- 入場曲はふたりが知ってる曲だと、ふたりで口ずさみながら入場できて楽しかった。(ウマ娘は自分もアニメは全部見た)
- 自分のプロフィールムービーのJ’S THEMAは、自分の生まれ年とJリーグ開幕年が同じなのでこだわった。結果としていい感じに曲調とムービーがハマった。
- 手紙朗読のあなたは新婦父が昔に「もし結婚式で手紙読むならこれ流してほしい」と言っていたのを覚えていたので使用した。
- エンドロールのrayはバラード過ぎず、アップテンポ過ぎずのいい線を突けたと思う。
- ガルパンのサントラは知らない人からしたらただのオーケストラ曲に聞こえるので使いやすかった。
- ケーキ入刀のオリジナルスターは、入刀と同時にイントロから流し始めてもらったが、そのあとファーストバイトのタイミングと「Are you ready!?」のフレーズのタイミングが思いのほか近かったので、演出として事前に決めておけばよかった。
- ウェディングプランナーの方が自分らがオタクなのを見て、音響担当スタッフをオタクの人に割り当ててくれた。そのおかげで、音響スタッフと演出決めるのはかなりスムーズにいった。(ほぼ全曲ご存じだった)
まとめ
「映像に残す」「演出に使う」のであれば、セットリストを決めるのに著作権問題はかなりネックになる。式場によってこの辺の取り扱いは違うと思うので、以上のことをあらかじめ知っておいたうえで、式場見学の際に聞いてみると式場を決める判断材料のひとつになると思う。オタク夫婦で挙式の予定がある方は参考にしてみてください。
宣伝
自分が挙式した式場がものすごくよい式場だったので宣伝します。
さいたま市西区のアルタビスタガーデンです。
親会社が映像制作会社なので、記録映像にこだわっています。「終わったあとに残るのは写真と映像だけ」ということをかなり協調されています。
また、一般に披露宴中は友人や会社の人との交流の時間が長くなりがちで、当日は両親や家族との時間をとることが難しいですが、ここの式場は家族との時間を大切にしており、ファミリータイムという両親とお話する時間をしっかり確保してくれるのが特徴です。
駅から遠いことが難点(当日ゲスト6人くらい遅刻してきた)ですが、そのぶん会場は広いので、コロナ禍の挙式でソーシャルディスタンスを確保することができました。披露宴会場のテーブル間が広いとドレス姿でも歩きやすいし、エスコートする側も気を使わなくて楽です。完全にバリアフリーで、ゲストが入っていけるところは車いすでも入っていけるようになっており、車椅子のゲストも安心です。
普段はレストランをやっているので、記念日にお食事するなど挙式後も遊びに来ることができます。
知り合いであれば紹介しますので連絡待ってます。

2万円ロードバイク 21technology 700Cについて
近年の自転車ブームによって,Amazonで非常に安い価格でロードバイクを購入することができるようになりました。こういうロードバイクの存在自体は知っていたのですが,今回Amazonで2万円で販売されているロードバイクを持っている友人と走る機会ができたので,スポーツ自転車を9年乗っている人間が見た,触った所感を残します。
21technologyとは
初めて聞いたメーカーだったので調べてみました。
ちゃんとしたHPがあって本社工場も福岡市で,その辺の信頼はありそうです。おそらく中華の謎のメーカー含めても最も安い価格で自転車を作って売っている会社のようです。クロスバイクもロードバイクもMTBも2万円を切っています。普通こんな価格でスポーツ自転車を売って利益が出せるわけがないので,なにか画期的な設計製造販売プロセスがありそうです。

21technology 700Cモデル実車
見た目のスッキリ感に反して,とにかくめちゃくちゃ重いです。一体どこにこんな重さが詰まっているのかと思ったがおそらくホイールです。おそらくGIANTのEscapeのほうが軽かった気がします。
変速は2x7の14速で,ステムの脇にレバーがある珍しいタイプでした。ディレイラーはSHIMANOのTourneyで,ママチャリによく使われているやつでした。ギア比は見るの忘れました。フロントディレイラーは2速でもディレイラー位置を4段階に調整できるものが多いですが,これは2段階です。リアが7速だから不要ということでしょう。
タイヤは28Cでスポークは36本あり,かなりハードな使い方をしても大丈夫そうです。デフォルトで入っているチューブのバルブは仏式のようです。
ブレーキはキャリパータイプで,やはり安いなりに効きはあまりよくないです。補助ブレーキがついていますが,こっちは高速走行時はほぼ使えないでしょう。テクトロのカンチブレーキを思い出しました。


変速レバーがステムの脇にある
フロントはH/L表記


あとは泥除け用のダボ穴が充実していますが,シートステーに穴はないのでキャリアはつけるのは一工夫必要です。面白かったのが,リアの反射板をつける用の台座があったことです(上の写真のかかとの後ろにあるやつ)。ここにはお金をかけてフレーム成型するのかと思いました。サドルは非常に柔らかくお尻にやさしい作りになっており,乗っている本人もお尻の痛みは感じていないようでした。
輪行はできるのか
結論から言うと,かなり大変です。通販で買ったときに前輪は外されて送られて来るらしいので,前輪のシャフトはクイックリリースタイプなのですが,後輪がスタンドと一緒に完全に15mmナットで固定されています。今回これを外すのがめちゃくちゃ大変でした。(自分がやったわけではなく,LINEで遠隔指示した)
しばらく屋外に放置すると錆びて固着してなかなか外れません。2時間近く格闘してダメでした。結局自転車屋に持ち込んで外してもらうことになりました。15mmというのが非常にマイナーな規格らしく,ソケットがその辺では手に入らないというのがまた厄介でした。
このように,外すことは全く想定されておらず,特に初心者にはかなり難しいのではないかと思います。クイックリリース化するにしても,シャフトごと交換になるので,特殊な工具が必要になるほか,玉当たり調整などかなりシビアな作業になるので,自転車屋に投げることになると思います。

規格はロードバイクなので,130mmエンド金具が使えて,オーストリッチの縦型輪行袋にもちゃんと収まりました。しかし,このナットが外れて輪行状態にできたとしても,輪行解除も大変でした。フレームの後輪軸を受ける穴の位置の精度が非常に悪く,フレームを手で歪めながらはめることになりました。こんなことは今までどんなスポーツ自転車でもなかったのでビックリです。
このように前後輪を外す輪行はまず想定されていません。前輪だけ外すタイプの輪行袋を使うしかないようです。(鉄道各社のルールによっては前輪だけ外すタイプの輪行袋では輪行できない可能性があります)
どんな人に薦められるか
安い,丈夫,重い,輪行が難しいといった特徴から考えると,主に通勤通学で楽に走りたいという人向けだと思います。トラブルが起きた時に柔軟に対応できるようにするというよりは,トラブルを起こさないという思想で設計製造されているように思えます。
今回この自転車の持ち主の友人はこれで箱根を登ったのですが,本人が普段からかなり運動,トレーニングしているからなしえたことだと思います。運動不足の人がこれに乗って箱根を登ろうと思ったら地獄を見ると思います。自分はやりたくないですね。
新しくロードバイクを買って,まじめに運動しようと思っている人はこれを買うべきではありません。5-10万円出してGIANTやBianchiから入ったほうがあとあと後悔しないと思います。逆に通勤通学がママチャリで辛いという人には,超格安でロードバイクが手に入ってスイスイ進むので適したロードバイクだと思います。
コミケに始発で行けるお得な物件をPythonを使って探そう #3 賃料相場比較編
#2でコミケに始発で行ける駅の特定ができたので,今回はその中で賃料相場の安いエリアを探します。
saddlenreport.hatenablog.jp
saddlenreport.hatenablog.jp
23区の賃料相場
まず東京23区の一人暮らし物件の賃料相場を見てみます。対象はワンルームと1Kの物件です。
Pythonを使って,#1で出力した賃貸データcsvから箱ひげ図を作りました。Pythonを使うと箱ひげ図の作成が驚くほど簡単でした。


葛飾区にもひとつだけぶっ飛んだ外れ値があるので見てみます。

外れ値が大きくて見づらいので拡大します。
比較のために名古屋市の相場を見てみます。
では最も賃料相場が高い東京都港区をさらに細かく字ごとに見ていきます。

このようにいろんな単位で賃料相場を見ることができるようになりました。
コミケに始発で行ける駅で最も安いエリアはどこか
東京23区に加え,西東京市(保谷駅),千葉県内京葉線沿線,京浜東北線埼玉神奈川県沿線の賃貸データをマージしてひとつの賃貸データファイルにします。約100,000件の物件データをもつファイル(約35MB)になりました。その100,000件の物件データから,最寄り駅が国際展示場駅に5:43までに到着できる駅に絞ります。ここでいう最寄り駅は,物件情報に3つ書いてある最寄り駅の1番目の駅を指します。この絞り込みもPythonを使ってやりました。

次に賃料相場が安い駅40
でも最低でも家賃は5万円見ておかないといけなさそうです。保谷ですでに中央値が5万円を上回っています。ちなみに山手線内の駅で最も安いのは西日暮里駅でした。
コミケに始発で行けるお得な物件をPythonを使って探そう #2 コミケ駅別始発到着時刻調査編
#1に続き,今回はコミケに始発で行ける駅を特定します。
saddlenreport.hatenablog.jp
同じくwebスクレイピングを使用しますが,前回とは少しやり方が異なります。
最終結果だけ見たい人は「首都圏の各駅から始発で国際展示場に何時に着けるか」までとんでください。
調べたい駅の一覧のcsvの作成
以下のようなcsvを用意します

そのまま駅名を羅列します。路線別にまとめて並べています。複数路線が乗り入れる駅は路線の数分重複しています。こうすることで,初電の列車がどこ始発なのかがわかりやすくなります。(例えば京浜東北線の南行初電は南浦和駅始発)
このときなんの文字コードで書いたかを確認しておく必要があります。駅データの一覧は以下のサイトからフリーでダウンロードできるので活用しました。このデータはutf-8で書かれています。
ekidata.jp
コード
コード自体は短くまとめることができます。
from bs4 import BeautifulSoup from selenium import webdriver import csv import pprint import pandas as pd from pandas import Series, DataFrame import time import sys import unicodedata sta =[] filename = 'sotetsu' csvname = filename + '.csv' for cols in csv.reader(open(csvname), delimiter=','): val = cols[0] sta.append(val) fare = [] deptime = [] arrtime = [] # Chrome用ドライバー読込 v_browser = webdriver.Chrome('D:\python\chromedriver.exe') # 路線検索サイトを開く v_browser.get('http://transit.yahoo.co.jp') for i in range(len(sta)): # サイトの出発駅の場所を特定 v_sfrom = v_browser.find_element_by_id("sfrom") # 出発駅を入力 v_sfrom.send_keys(sta[i]) # サイトの到着駅の場所を特定 v_sto = v_browser.find_element_by_id('sto') # 到着駅を入力 v_sto.send_keys('国際展示場') #始発を選択 radioButton = v_browser.find_element_by_id("tsFir"); radioButton.click(); v_sto.submit() # 運賃を取得し、円を取り除く v_fare = v_browser.find_element_by_class_name('fare').text.replace('円','') # 運賃からカンマを取り除く v_fare_int = v_fare.replace(',','') #出発時刻を取得 v_deptime_0 = v_browser.find_elements_by_class_name('time') v_deptime_1 = v_deptime_0[1].text.split('→') v_deptime = v_deptime_1[0] #運行に異常がある場合,[!]が出るので削除 if '[!]' in v_deptime: v_deptime = v_deptime.replace('[!]','') #到着時刻を取得 v_arrtime = v_browser.find_element_by_class_name('mark').text print(str(i+1) + '/' + str(len(sta))) print(sta[i]) print(v_fare_int) print(v_deptime) print(v_arrtime) fare.append(v_fare_int) deptime.append(v_deptime) arrtime.append(v_arrtime) #プログラムを10秒間停止する(スクレイピングマナー) time.sleep(10) v_browser.get('http://transit.yahoo.co.jp') # ブラウザを閉じる v_browser.close() #各配列をシリーズ化 sta = Series(sta) fare = Series(fare) deptime = Series(deptime) arrtime = Series(arrtime) output_df = pd.concat([sta,deptime,arrtime,fare], axis=1) output_df.columns=['出発駅','出発時刻','到着時刻','運賃'] output_df = output_df.rename_axis('MyIdx').sort_values(['到着時刻','MyIdx']) output_df.to_csv(filename + '_res.csv', sep = '\t',encoding='utf-16') print('csv出力完了')
上記のコードは自分で作成した相鉄線の駅一覧のデータシート"sotetsu.csv"を読み込んで始発到着時刻を調べるプログラムになっています。
やっていることは
となっています
経由地を設定したいときは以下のコードを追加します
#サイトの経由駅の場所を特定 v_svia1 = v_browser.find_element_by_id('svia1') #経由駅を入力 v_svia1.send_keys('新木場')
JR総武中央緩行線の出力結果です
経由駅の設定による結果の差
いろんな路線でこの処理をしていて気づいたのは,経由駅の設定の仕方で結果が変わってしまうことです。当然だろうと思うかもしれないですが,「経由駅を設定しない検索結果」よりも「経由駅を設定した検索結果」のほうが到着時刻が早くなるケースがありました。
以下に京浜東北線の2つの処理結果を示します。

試しに,大井町から国際展示場で始発検索を2パターンやってみると,
このように経由地の設定の仕方で到着時刻が変わってしまい,「本当の始発」の特定が現状難しいです。他にゆりかもめを考慮して豊洲経由にすると,また結果が変わります。じゃあ全部新木場経由で検索すればいいじゃないか,と思うかもしれませんがそうすると本来大崎始発に乗れる駅の特定が難しくなります。
これを解決するには経由駅を複数パターン用意してそれぞれ検索し,最も早く到着できるものを記録する,という手段が考えられます。処理時間が数倍になるので自分はやっていません。もしもっとスマートな方法があったら教えてください。
