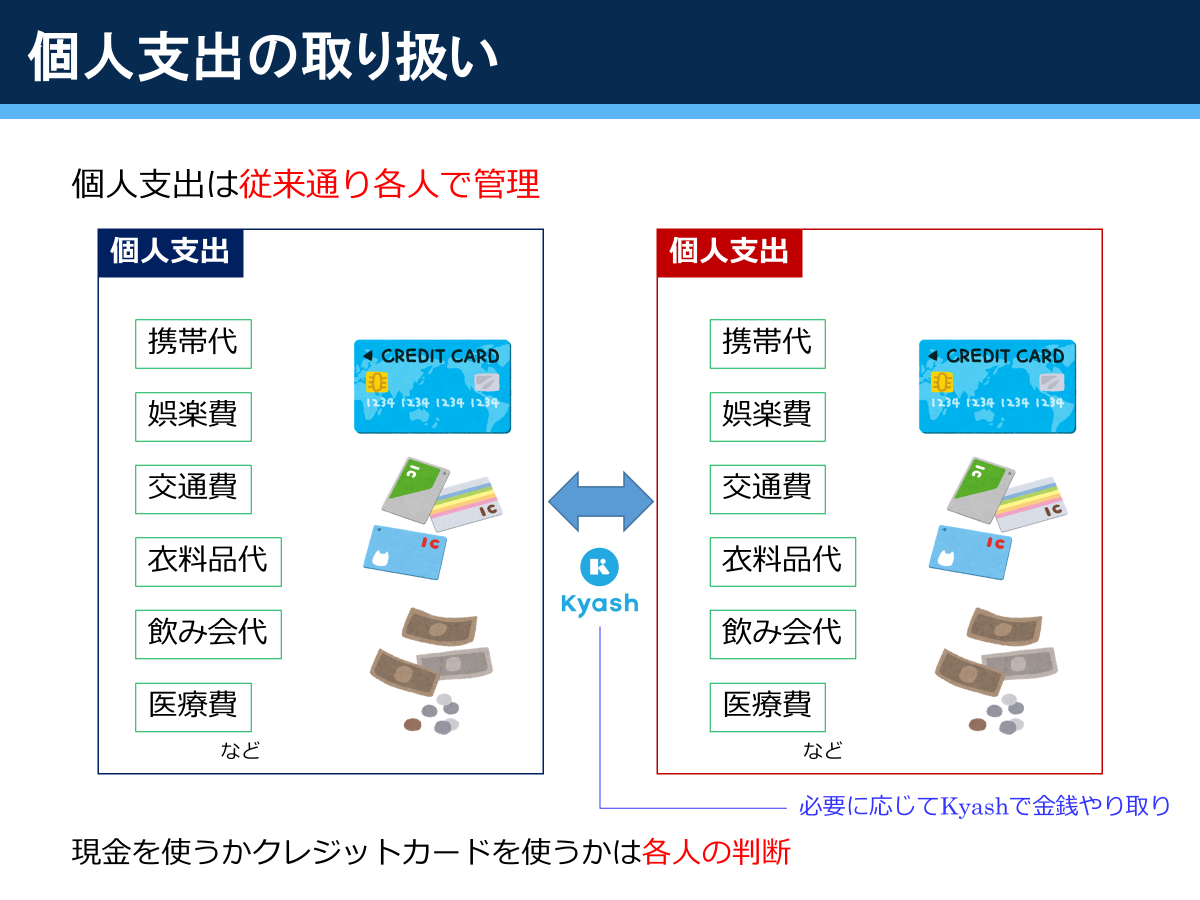
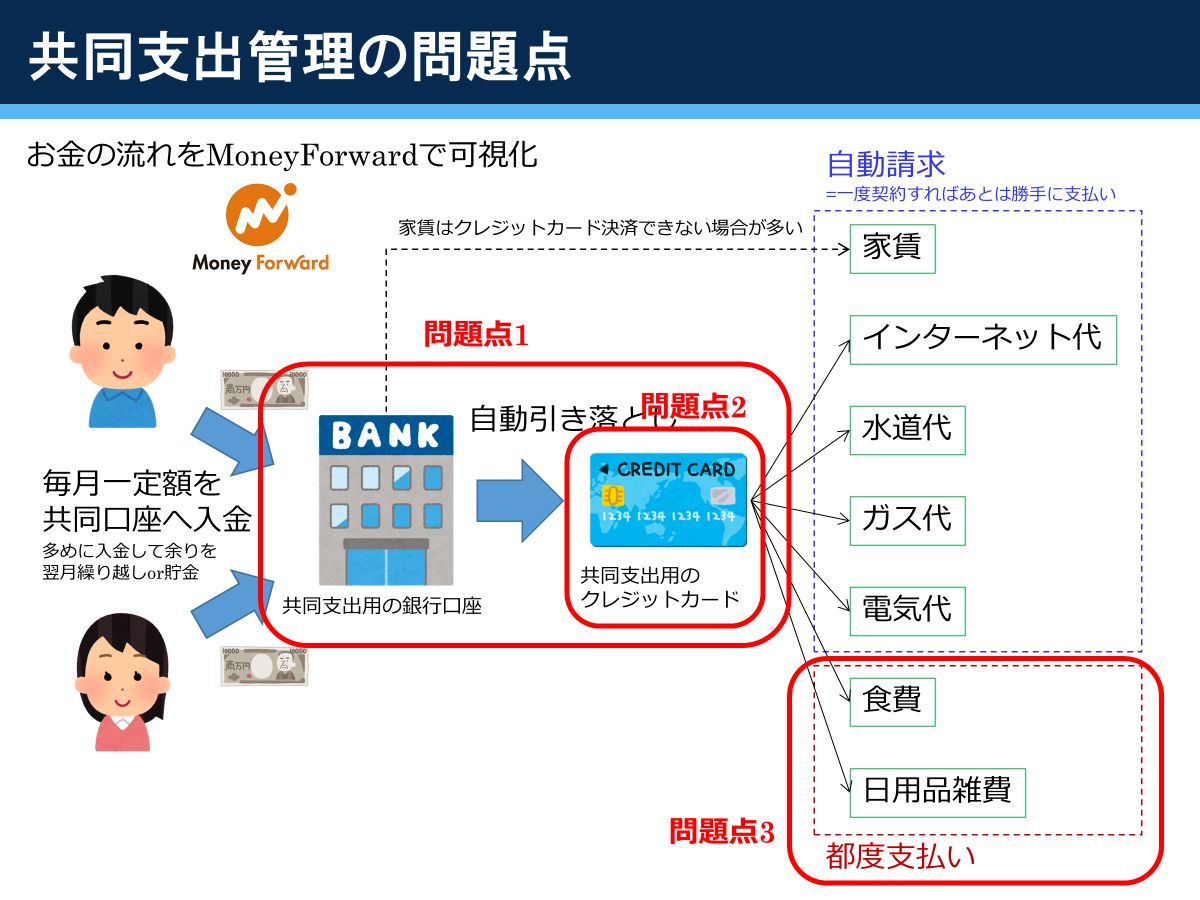
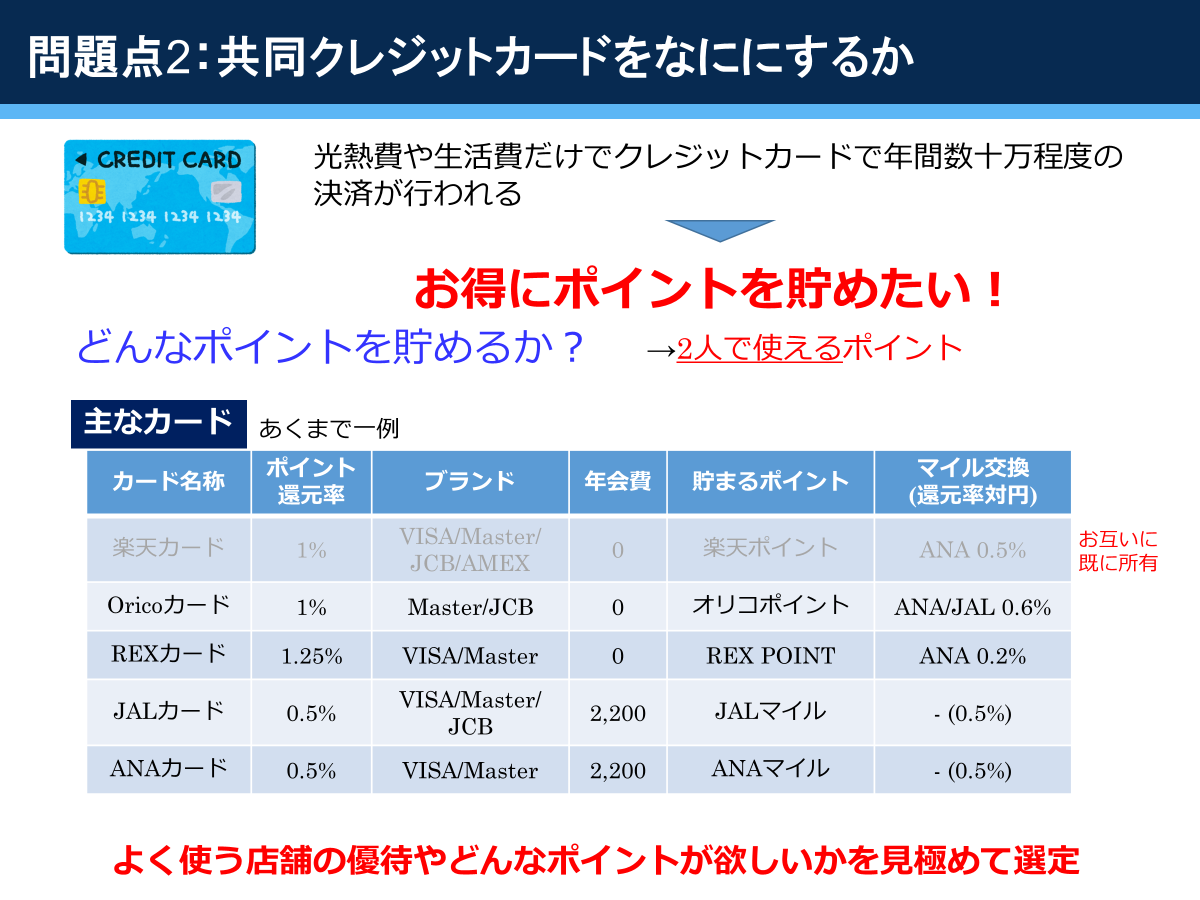
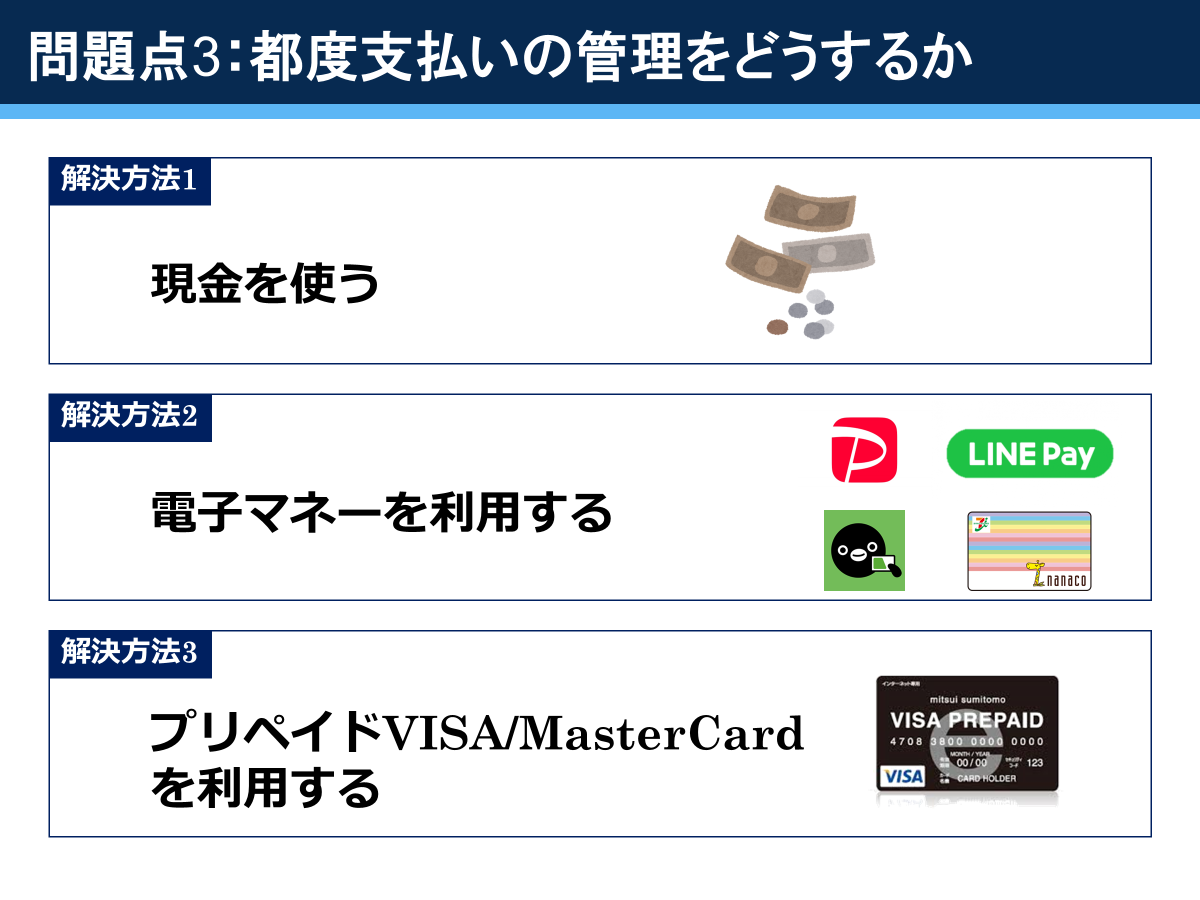
物件を探すにあたって,まずは物件情報を一通りそろえなければなりません。そこで,まずはWebスクレイピングでSuumoから物件情報を取得して,csvに書き出します。
以下の記事を参考にしました。
www.analyze-world.com
ベースのコードはこの記事のコードです。そこに少し手を加えました。
前処理
必要なライブラリをインポートして,Suumoのページ数を取得。
from bs4 import BeautifulSoup
import urllib3
import re
import requests
import pandas as pd
from pandas import Series, DataFrame
import time
import sys
import unicodedata
print('URLを入力してください')
url=input()
print('出力ファイル名を入力してください(拡張子不要)')
csvname=input()
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c,"html.parser")
summary = soup.find("div",{'id':'js-bukkenList'})
body = soup.find("body")
pages = body.find_all("div",{'class':'pagination pagination_set-nav'})
pages_text = str(pages)
pages_split = pages_text.split('</a></li>\n</ol>')
pages_split0 = pages_split[0]
pages_split1 = pages_split0[-3:]
pages_split2 = pages_split1.replace('>','')
pages_split2 = pages_split2.replace('"','')
pages_split3 = int(pages_split2)
print(str(pages_split3) + 'pages')
ここで入力するSuumoのURLは,検索結果の最初の1ページ目のものです。

 相場を見るにはあまり条件を絞りすぎないほうがよいこれで検索ボタンを押して最初に出てきたページのURLを入力します。そのあと,ページ下部にあるページ遷移ボタンの末尾(「次へ」の左にある数字)を読んで,全ページ数を取得します。
相場を見るにはあまり条件を絞りすぎないほうがよいこれで検索ボタンを押して最初に出てきたページのURLを入力します。そのあと,ページ下部にあるページ遷移ボタンの末尾(「次へ」の左にある数字)を読んで,全ページ数を取得します。
次にURLのリストを作ります。
urls = []
urls.append(url)
for i in range(pages_split3-1):
pg = str(i+2)
url_page = url + '&page=' + pg
urls.append(url_page)
name = []
address = []
pref = []
city = []
ward = []
town = []
locations0 = []
loc0_rosen =[]
loc0_sta =[]
loc0_bus=[]
loc0_foot = []
locations1 = []
loc1_rosen =[]
loc1_sta =[]
loc1_bus = []
loc1_foot = []
locations2 = []
loc2_rosen =[]
loc2_sta =[]
loc2_bus = []
loc2_foot = []
age = []
height = []
floor = []
rent = []
admin = []
others = []
floor_plan = []
area = []
detail_urls=[]
rent_tot=[]
Suumoの検索結果の2ページ目以降はURL末尾に"&page=2"とついているだけなので,手動でこれをつけてやってあとはfor文を回してあげます。あとは取得するデータを格納する空のリストを準備します。もっとスマートな方法があったら教えてください。
住所の取得
次に物件の住所を取得します。あとで解析がしやすいように,都道府県,市区町村,政令区,字以下で分けました。
for url in urls:
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c)
summary = soup.find("div",{'id':'js-bukkenList'})
cassetteitems = summary.find_all("div",{'class':'cassetteitem'})
for i in range(len(cassetteitems)):
tbodies = cassetteitems[i].find_all('tbody')
room_number=len(tbodies)
subtitle = cassetteitems[i].find_all("div",{
'class':'cassetteitem_content-title'})
subtitle = str(subtitle)
subtitle_rep = subtitle.replace(
'[<div class="cassetteitem_content-title">', '')
subtitle_rep2 = subtitle_rep.replace(
'</div>]', '')
subaddress = cassetteitems[i].find_all("li",{
'class':'cassetteitem_detail-col1'})
subaddress = str(subaddress)
subaddress_rep = subaddress.replace(
'[<li class="cassetteitem_detail-col1">', '')
subaddress_rep2 = subaddress_rep.replace(
'</li>]', '')
if '県' in subaddress_rep2:
temp_address1=subaddress_rep2.split('県',1)
pref_temp1=temp_address1[0]+'県'
elif '都' in subaddress_rep2:
temp_address1=subaddress_rep2.split('都',1)
pref_temp1=temp_address1[0]+'都'
if '市' in temp_address1[1]:
temp_address2=temp_address1[1].split('市',1)
city_temp1=temp_address2[0]+'市'
elif '区' in temp_address1[1]:
temp_address2=temp_address1[1].split('区',1)
city_temp1=temp_address2[0]+'区'
elif '町' in temp_address1[1]:
temp_address2=temp_address1[1].split('町',1)
city_temp1=temp_address2[0]+'町'
elif '村' in temp_address1[1]:
temp_address2=temp_address1[1].split('村',1)
city_temp1=temp_address2[0]+'村'
if '区' in temp_address2[1]:
temp_address3=temp_address2[1].split('区',1)
ward_temp1=temp_address3[0]+'区'
temp_address4=temp_address3[1]
else:
ward_temp1 = None
temp_address4 = temp_address2[1]
uni = unicodedata.east_asian_width(temp_address4[-1])
if uni == 'F':
town_temp1=temp_address4[:-1]
else:
town_temp1=temp_address4
for y in range(len(tbodies)):
name.append(subtitle_rep2)
address.append(subaddress_rep2)
pref.append(pref_temp1)
city.append(city_temp1)
ward.append(ward_temp1)
town.append(town_temp1)
かなりパワープレーみたいな書き方になっています。例えばこの書き方だと,都城市や市原市のような地名に対応できません。全部対応させようするとかなり長いコードになりそうな気がしたので,今回はここまでにしました。
立地・築年数・建物高さの取得
駅から徒歩〇分や駅からバスで△分徒歩◇分のような立地と築年数と建物高さを取得します
Suumoの立地表記はだいたい以下2つの様式です。
ですがたまにイレギュラーがあります。Suumoの表記の仕方に特に決まりはないようで,例えば
のように書かれていることもあります。宇須ってなんだよと思いましたが,宇都宮線横須賀線を表しているようです。こういうイレギュラーがあるだけであとの解析が面倒になります。他に「車で〇分」だったりそもそも路線を書かずバス路線系統と停留所しか書かれていないものもありました。
tempcassette=cassetteitems[i]
sublocations = cassetteitems[i].find_all("li",{
'class':'cassetteitem_detail-col2'})
for x in sublocations:
cols = x.find_all('div')
for i in range(len(cols)):
text = cols[i].find(text=True)
if text != None:
split01 = text.split('/',1)
subloc_rosen = split01[0]
if '歩' in split01[1]:
split02 = split01[1].split(' 歩',1)
if ' バス' in split02[0]:
split03 = split02[0].split(' バス', 1)
subloc_sta = split03[0]
print(split03[1])
split04 = split03[1].split('分', 1)
subloc_bus = split04[0]
else:
subloc_sta = split02[0]
subloc_bus = None
subloc_foot = split02[1]
subloc_foot = subloc_foot.strip('分')
else:
subloc_rosen = None
subloc_sta = None
subloc_bus = None
subloc_foot = None
else:
subloc_rosen = None
subloc_sta = None
subloc_bus = None
subloc_foot = None
for y in range(len(tbodies)):
if i == 0:
locations0.append(text)
loc0_rosen.append(subloc_rosen)
loc0_sta.append(subloc_sta)
loc0_bus.append(subloc_bus)
loc0_foot.append(subloc_foot)
elif i == 1:
locations1.append(text)
loc1_rosen.append(subloc_rosen)
loc1_sta.append(subloc_sta)
loc1_bus.append(subloc_bus)
loc1_foot.append(subloc_foot)
elif i == 2:
locations2.append(text)
loc2_rosen.append(subloc_rosen)
loc2_sta.append(subloc_sta)
loc2_bus.append(subloc_bus)
loc2_foot.append(subloc_foot)
age_and_height = tempcassette.find('li', class_='cassetteitem_detail-col3')
_age = age_and_height('div')[0].text
_height = age_and_height('div')[1].text
if _age == '新築':
_age = _age.replace('新築','0')
else:
_age = _age.strip('築')
_age = _age.strip('年')
for i in range(room_number):
age.append(_age)
height.append(_height)
歩きを伴わない立地は後の処理で面倒になりそうだったので削除しました。
新築は0年に置き換え,すべて数値型で扱えるようにします。
住所と同様に同じ建物の部屋数分だけ配列に追加します。
このとき,なぜかtempcassetteという仮の別の変数に入れ直さないと動きませんでした。結局原因はわかっていません。
賃料など部屋ごとのステータスの取得
最後に部屋ごとの各ステータスを取得します。
tables = summary.find_all('table')
rows = []
for i in range(len(tables)):
rows.append(tables[i].find_all('tr'))
data = []
for row in rows:
for tr in row:
cols = tr.find_all('td')
if len(cols) != 0:
_floor0 = cols[2].text
_floor0 = re.sub('[\r\n\t]', '', _floor0)
if _floor0 == '-':
_floor = '1'
else:
split_fl = _floor0.split('-')
_floor = _floor0[0].strip('階')
_rent_cell = cols[3].find('ul').find_all('li')
_rent = _rent_cell[0].find('span').text
_rent = _rent.replace(u'万円',u'')
_admin = _rent_cell[1].find('span').text
if _admin == '-':
_admin = _admin.replace('-','0')
else:
_admin = _admin.strip('円')
_admin = int(_admin)/10000
_rent_tot = float(_rent) + float(_admin)
_rent_tot = round(_rent_tot,2)
_deposit_cell = cols[4].find('ul').find_all('li')
_deposit = _deposit_cell[0].find('span').text
_reikin = _deposit_cell[1].find('span').text
_others = _deposit + '/' + _reikin
_floor_cell = cols[5].find('ul').find_all('li')
_floor_plan = _floor_cell[0].find('span').text
_area = _floor_cell[1].find('span').text
_area = _area.replace(u'm2',u'')
_detail_url = cols[8].find('a')['href']
_detail_url = 'https://suumo.jp' + _detail_url
text = [_floor, _rent, _admin, _others, _floor_plan, _area, _detail_url, _rent_tot]
data.append(text)
for row in data:
floor.append(row[0])
rent.append(row[1])
admin.append(row[2])
others.append(row[3])
floor_plan.append(row[4])
area.append(row[5])
detail_urls.append(row[6])
rent_tot.append(row[7])
print(len(data))
print(url + '完了')
time.sleep(10)
部屋ごとにステータス欄のhtmlコードを配列に格納し,それを分解して各ステータスを指定の配列に追加していきます。
敷金礼金は数値化していません。必要になったらしようかなと思っています。
出力処理
csvに出力します。
name = Series(name)
address = Series(address)
pref = Series(pref)
city = Series(city)
ward = Series(ward)
town = Series(town)
locations0 = Series(locations0)
loc0_rosen = Series(loc0_rosen)
loc0_sta = Series(loc0_sta)
loc0_bus = Series(loc0_bus)
loc0_foot = Series(loc0_foot)
locations1 = Series(locations1)
loc1_rosen = Series(loc1_rosen)
loc1_sta = Series(loc1_sta)
loc1_bus = Series(loc1_bus)
loc1_foot = Series(loc1_foot)
locations2 = Series(locations2)
loc2_rosen = Series(loc2_rosen)
loc2_sta = Series(loc2_sta)
loc2_bus = Series(loc2_bus)
loc2_foot = Series(loc2_foot)
age = Series(age)
height = Series(height)
floor = Series(floor)
rent = Series(rent)
admin = Series(admin)
others = Series(others)
floor_plan = Series(floor_plan)
area = Series(area)
detail_urls = Series(detail_urls)
rent_tot = Series(rent_tot)
suumo_df = pd.concat([name, pref,city, ward,town, loc0_rosen,loc0_sta,loc0_bus,loc0_foot,loc1_rosen,loc1_sta,loc1_bus,loc1_foot,loc2_rosen,loc2_sta,loc2_bus,loc2_foot, age, height, floor, rent, admin,rent_tot, others, floor_plan, area, detail_urls], axis=1)
suumo_df.columns=['マンション名','都県','市区町村','区','字','立地1_路線','立地1_駅','立地1_バス','立地1_徒歩[分]','立地2_路線','立地2_駅','立地2_バス','立地2_徒歩[分]','立地3_路線','立地3_駅','立地3_バス','立地3_徒歩[分]',\
'築年数','建物の高さ','階層','賃料料[万円]','管理費[万円]','合計賃料[万円]', '敷/礼/保証/敷引,償却','間取り','専有面積[m2]', '詳細URL']
suumo_df.to_csv('resdata/' + csvname + '.csv', sep = '\t',encoding='utf-16')
print('csv出力完了')
シリーズ化するのが面倒です。一括でできるコマンドはないのか…
文字コードはUTF-16で,タブ区切りで出力していますが特に意味はないです。参考にした記事を書いた方がそうしていたからです。
これで以下のようなcsvを出力することができます。 東京都練馬区の例試しに東京都中央区の一番賃料が高い1Kの物件を見てみましょう
東京都練馬区の例試しに東京都中央区の一番賃料が高い1Kの物件を見てみましょう STUDIOと書いてあるが…
STUDIOと書いてあるが…
KDXレジデンス日本橋人形町 日比谷線人形町徒歩3分で家賃月113万円!
どういう層に需要があるんでしょうか…
一連の処理の問題として感じられたのは以下の通り
- すべての市区町村名に対応できない
- 立地表記ゆれに対応できない
- 処理中にネット回線が不安定になると処理失敗になる
- 少ないページ数に対応できない
上2つは前述のとおりです。
3つ目に関して,非常に多くの物件を取得しようすると長い時間がかかります。その途中でネットの回線が不安定になると,処理が止まりいままでの処理がなかったことになります。これは一番最後にcsv出力する仕様になっているためです。
4つ目は,ページ数取得がうまくいきません。以下のページ番号リンクの「...」の右の番号を参照しているからです。「...」が現れないケースはページ数を取得できません。

また,1回だけですが,処理中に物件が消されて最初に取得したページ数より少ないページになってしまうケースがありました。これは非常にレアケースなので無視しました。
以上です。次はコミケに始発で行ける駅を特定します。